
Since its recent open source release, Wasabi has gotten a lot of love. On one side, there are the open source community developers who liked it (244 stars as of this blog publishing date) and submitted a number of enhancement pull requests. On the other side, there are individuals as well as small and large companies that have already adopted, or are starting to adopt, the platform for their experimentation needs. These range from large consumer electronics, to healthcare, to travel, to financial technology firms.

Whether you’re a developer wanting to contribute to Wasabi or an operations engineer looking to deploy it at scale in the cloud or in your own data center, this blog will give you some background on the architecture behind Wasabi and its deployment options.
A/B Testing as a service
The core principle of Wasabi is A/B Testing as a service. Therefore, everything that you do with Wasabi is just a RESTful API call away:
- Create an experiment with its buckets, user filtering and segmentation rules, mutual exclusion for conflicting experiments resolution, and sampling rate for percentage of customer traffic allocation
- Group experiment into applications
- Assign your customers into the experiment and its buckets
- Track your customer experiences by recording their impressions and actions
- Start, modify, stop, or terminate the experiment
- Track experiment results of your experiment and its buckets via analytics
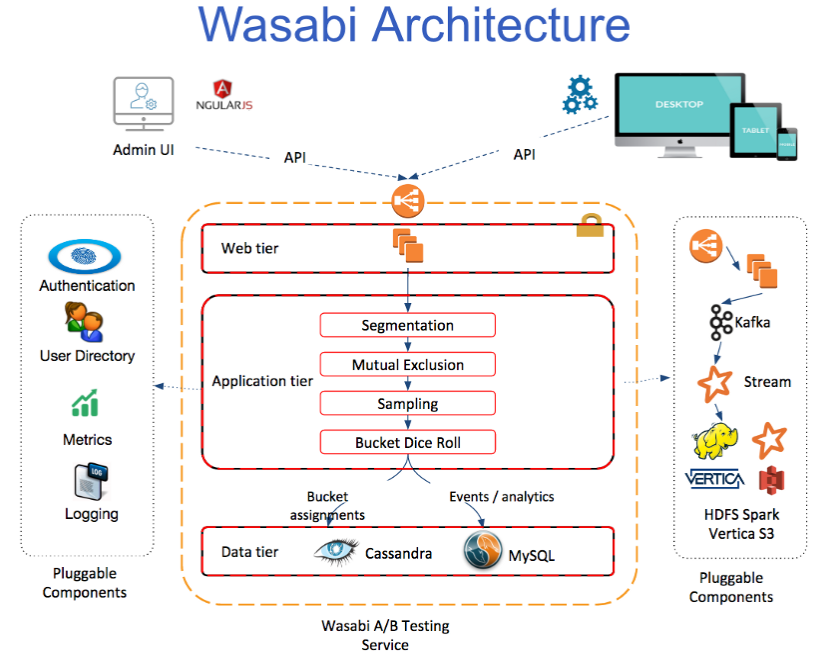
Wasabi architecture
To service RESTful API requests, Wasabi was designed as a web service with standard web, application, and data tiers. It also has an interface to manage experiments. In addition to the core service itself, Wasabi has a set of pluggable hooks to integrate with your existing systems, if you already have them in place. These include authentication, user directory, system monitoring, and offline big data analytics integrations. All these also include default implementations out of the box.

Admin UI
Like having a visual tool? You got it! Wasabi provides an administrative interface to manage your experiments in one place. Behind the scenes the Admin UI calls experiment management and analytics RESTful APIs, from creating and starting an experiment, to tracking which bucket is the winner. The Admin UI was built using AngularJS. You can control who has access to the Admin UI through pluggable authentication schemes, including integration with your own LDAP system or you can use the default property-based scheme. You can also integrate your corporate directory to manage access to Wasabi’s applications and experiments. Admin UI is extensible through plugins to allow for more experiment management functionality.
Integration with Wasabi
Once your experiment is setup, you can easily integrate your end-user application with Wasabi through the RESTful APIs. No matter if you’re running a web, mobile, or desktop application and which programming language your application uses (JavaScript, PHP, Java, Python, C#, or others), just make calls to Wasabi! And there’re only few key APIs to integrate with:
- Assign user into a single experiment, or a list of experiments, or page — a reference to associated experiments
- Record user’s impressions or actions, such as clicking a button
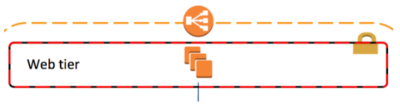
Web tier
Wasabi service itself starts with the web tier. It’s composed of the load balancer, such as an Elastic Load Balancer (ELB) on Amazon Web Services (AWS). The web service itself is an Apache httpd server, which handles HTTP connections, SSL termination and URI redirection. Need to throttle or block malicious API calls to Wasabi? This tier is the right place to do this.
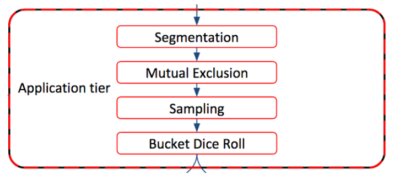
Application tier
This is the “meat” of Wasabi. Application tier runs on top of a lightweight and powerful Jetty web server. Jackson JAX-RS handles Wasabi RESTful API requests: from experiment and application management to user assignments, event recording, and analytics. Java JVM object management is done through Guice. Code flows from API handlers, to business logic, to data repository management. Metrics are enabled through JMX APIs. Logging is standardized via Java SLF4J and its Logback implementation.

Data tier
Wasabi’s data tier features both Apache Cassandra and MySQL. Cassandra enables single-digit millisecond user to bucket assignments. MySQL is used to record and aggregate analytical events, including impressions and actions. If you have one already, Wasabi enables a pluggable way to stream both assignments and events in real-time to your big data analytics cluster for further off-line analysis.
Deployment
For local machine deployment and development, Wasabi is instrumented to use Docker containers. When you bootstrap and start Wasabi, it will run 3 containers:
- wasabi-main — for web and applications tiers
- wasabi-cassandra — for Cassandra on the data tier
- wasabi-mysql — for MySQL on the data tier
For running Wasabi at scale, however, we recommend direct deployment of packages on servers. Out of the box, Wasabi provides RPM and Debian Linux package generation for the Admin UI and the main application. For dependent Apache httpd, Apache Cassandra, and MySQL, you can obtain them from open source or enterprise repositories.
Next steps
I hope this gives you a good background on Wasabi architecture, technology stack, and deployment options. Since its open source release, a lot of performance optimizations have been applied to Wasabi to deliver single-digit millisecond latency for assignment and event recording APIs. Next for Wasabi is provide improved and more relevant analytics and continue enhancing experiment management experience, such as experiment tagging.
Get involved!
If you have any further questions on developing or deploying Wasabi, please reach out to our open source community via Gitter, Github or data@intuit.com. Wasabi will continue to evolve, so become a contributor and grow with us!
Leave a Reply